Note: This is simply a mirror of the encoding guidelines at the SARIT website, which was down as of Feb. 19, 2018. The guidelines were written by Patrick McAllister, Liudmila Olalde, and Andrew Ollett in 2015; I personally have changed a few things in my own projects, but by and large these guidelines will still get you to good TEI.
Encoding Guidelines
This document presents guidelines for the creation of digital texts in Sanskrit, Prakrit, and other Indian languages.
If you wish to submit texts please contact Dominik Wujastyk (wujastyk@gmail.com).
These guidelines are maintained by SARIT (http://sarit.indology.info). SARIT maintains a collection of digital texts that conform to the standards of the Text Encoding Initiative (TEI) and provides tools for browsing and seaching these texts. These guidelines have two main purposes:
- to document the standards that the SARIT project has followed in the creation of its own digital texts;
- to provide guidance for how to apply the TEI standards to texts in Sanskrit and other Indian languages;
- to promote the production of TEI-conformant digital texts in the community of Indian studies.
The guidelines come in two varieties: simple and full.
- The simple guidelines (this document) document the minimal level of encoding that SARIT requires of texts in its collections. These guidelines provide a straightforward path “from printed edition to digital text,” and should suffice for the purposes of most projects.
- The full guidelines supplement the simple guidelines. The TEI standards that SARIT follows allow for encoding features of a text that aren’t typically included in “plain” digital texts. The full guidelines provide guidance for these advanced features. If you want your digital text to reflect textual variation (in the form of a critical apparatus or otherwise), cross-references within the text or references to other texts, or any kind of controlled vocabulary (persons, works, places, etc.), then the full guidelines are for you.
Texts that are encoded according to the simple guidelines can always be “enhanced” at a later stage with the markup described in the full guidelines.
Introduction
Digital texts come in a variety of formats, but the texts distributed by SARIT are XML files that conform to standards of the Text Encoding Initiative (TEI).
What is XML?
In the days of publishing before word-processing, copy editors used to "mark up" an author's typed or handwritten manuscript for the printer, using written abbreviations to indicate structural points in the text, like headings, indents or font changes. XML is simply a collection of markup conventions for digital documents. Most web pages use XML or an XML-like form of markup. HTML is a special case of XML. The key feature of XML is its use of elements, which start and end with tags in angle-brackets, and signal some editorial intention relating to the text:
<p>This is a paragraph.</p>Elements can be nested within each other:
<p>This is <hi>highlighted text</hi>.</p>Elements can also be given attributes:
<p>This is <hi rend="bold">an element</hi>.</p>In a well-formed XML document, every starting tag corresponds to an ending tag, and vice versa, and all of the elements are arranged hierarchically and without overlapping. But in order to be useful, the document must use elements in a well-defined and standardized way. A document that formally defines what elements may be used in an XML document, and how they may be used, is called a schema.
Once you have well-formed and valid XML, what can you do with it? There are many computer programs that can read an XML text and do all sorts of interesting things. One of the first things you may want to do is to check that the file you have painstakingly prepared really is well-formed. That is the work of a so-called "XML Parser." It can check your text and flag up inconsistencies in the markup, making sure that it validates against a schema. But that is only the beginning.
Since XML provides a structure that computers can easily navigate, it is easy to find any part of a document. You can index these parts in a database for searching, or you can transform them into a format that human beings can read: HTML, RTF, or PDF. XML texts can be converted into almost any other format, or processed in many complicated ways using a super-strength version of search-and-replace called XSLT.
How do I type XML texts?
An XML document has no hidden codes, and can be typed with any writing program from the simplest editor to the most feature-rich word processor. Many modern programs have XML "modes" that provide things like syntax-highlighting or online help; others have been created specifically for typing XML. Several of these programs have XML Parsers built in to them, so that they can check your input as you go along and perhaps even format it nicely on the screen.
What is TEI?
The Text Encoding Initiative produces guidelines for encoding texts as XML documents and schemas for validating those documents. The TEI guidelines have been used, and continue to be used, in hundreds of text-encoding projects, and form the basis of many other subprojects (such as EpiDoc). They are actively maintained and well-supported by a growing number of applications, and hence they currently represent “The Right Way” to produce digital texts.
Structure, not presentation
We want to reflect the structure of text, and not the presentation of
the text on the pages of a printed edition. This means that we typically do not encode
formatting such as bold face, italics, centered text, and so on. Rather, we encode the
logical features of the text that these formatting decisions represent. Although TEI
provides a rendering attribute (@rend) for many elements, we do not
recommend using it: if text is rendered in a certain way, try to figure out why
it is rendered that way, and then encode the structural reasons for that presentational
choice. Thus, if a text is centered on the page because it represents a colophon, use
<trailer> rather than <p rend="center">.
Getting started
All SARIT documents start the same way. The file begins with an XML declaration, a processing instruction that tells whatever program opens the document that it is written in XML. This XML declaration is always the same:
<?xml version="1.0" encoding="utf-8"?>
All valid XML files must have one, and only one, top-level element. Since SARIT documents are TEI documents, this top-level element is going to be <TEI>. This means that the second line of the file, after the XML declaration, will look something like the following:
<TEI xml:id="sarit__XML-ID_HERE" xmlns="http://www.tei-c.org/ns/1.0">
This
element has two attributes. The xml:id is a unique identifier for the
document. Your choice for this unique identifier will depend on your project. The
xmlns attribute tells whatever program opens the document that the
names of the XML elements are the names defined by the Text Encoding Initiative: for
example, that the element <p> is what the TEI defines as
<p>, and not what any other authority defines as
<p>.
The last line of the document will close the <TEI> element, and hence
it will always be </TEI>.
Further details
Comments
The XML processor will ignore anything that is contained between <!-- and
-->.
The xml:id and xml:lang attributes
The xml:id attribute assigns a unique identifier to an element, so that the
element can be referenced from anywhere else in the document, or even in a corpus of
documents. But the functions that depend on unique identifiers—indexing and cataloguing,
for example—are better left to automatic processes. And since xml:ids need to be
unique, and need to have a certain format (NCName), it’s easy for humans to
introduce errors that will throw a wrench into these automatic processes. That’s why
SARIT recommends _against_ the use of xml:id attributes within a document.
If xml:ids are needed for technical reasons, it’s better to let those technical
reasons determine how these xml:ids are to be generated and assigned. A document will
still be valid if you use xml:ids, and there are certain cases (such as referencing
readings in a critical apparatus to the main text) where you might find xml:ids
useful. But in general, nothing is lost by omitting xml:ids, and often compatability
with certain programs (such as SARIT’s XML database) is gained by omitting them.
The xml:lang attribute, on the other hand, should be
used systematically and carefully when preparing a SARIT document. This attribute tells us
what language is represented by the text of the element to which it is attached. SARIT
follows the two-letter language codes defined by http://loc.gov/standards/iso639-2/, and in most cases
these language codes are followed by a code for the script, as follows:
-
en: English (in the Latin script by default); -
sa-Latn: Sanskrit in the Latin script (Roman transliteration); -
sa-Deva: Sanskrit in the Devanāgarī script. -
pra-Latn: Prakrit in the Latin script (Roman transliteration); -
pra-Deva: Prakrit in the Devanāgarī script.
See SARIT’s character-encoding guidelines regarding issues of script and transliteration.
The xml:lang attribute is heritable: if you say that a certain
element is in a certain language, then all of the children of that element are assumed
to be in the language as well. Thus we need to specify a language at the highest level
of its occurrence: <teiHeader> will almost always take the attribute
xml:lang="en", and <text> will almost always take
the attribute xml:lang="sa-Deva" or xml:lang="sa-Latn" (see
above). Apart from this initial specification, we only need to specify the language of
an element if it is different from the language of its parent element: for example, if
you have an English note to a Sanskrit text, you will generally give the
<note> element the xml:lang="en" attribute.
Dealing with whitespace
Because XML uses tags rather than whitespace elements (line-breaks and indentation) to mark the logical structure of the document, XML has no hard-and-fast rules for whitespace: a single element, consisting of a starting-tag, content, and an ending-tag, might occur on one, three, or forty lines. Different text editors also have different conventions for putting whitespace into XML documents.
XML processors usually trim the whitespace at the beginning and end of an element. (See
http://wiki.tei-c.org/index.php/XML_Whitespace#Trimming.) Usually this will not
change the actual text that you wish to encode. Whitespace requires attention, however,
when within an element text and XML elements occur side-by-side, that is, when using
inline XML elements (elements which have text before or after them). In cases like this,
it’s important to put meaningful spaces outside of the inline tags rather than
inside the tags,
thus:
<element>XYZ <element>ABC</element> XYZ</element>
Rather
than:
<element>XYZ<element> ABC </element>XYZ</element>
which will lose the spaces when it is processed.
The TEI Header
One of the advantages of using TEI is the ability to include all kinds of structured metadata. When we create a SARIT document, we are not just transcribing the text, but also providing the following:
- cataloguing information, for example the title and author of the text;
- information about the document’s source, such as the edition that the digital text is based upon;
- legal information, such as the license and authority under which the text is made available;
- information about the encoding of the document; and
- information about the revisions that have been made to the document over the course of its history.
All of this information is provided in a section of the document called the
header, which is contained in the element <teiHeader>.
<teiHeader> is a direct child of the top-level element
<TEI>. And since the metadata will typically be in English, we
typically specify the language of the <teiHeader> element with
xml:lang="en". The TEI Header has three obligatory sections: one for
the description of the file (<fileDesc>), one for the description of
the file’s encoding (<encodingDesc>), and one to record the file’s
history (<revisionDesc>). We’ll talk about these three sections in
order. But SARIT also provides a template document that shows how the header should be
structured (https://github.com/sarit/SARIT-corpus/blob/master/00-sarit-tei-header-template.xml).
It is important to distinguish between the work and a specific representation of that work. A work is an abstract object, such as Hamlet or Abhijñānaśakuntalā considered as ideas in the mind. A printed edition of a work and a digital edition of a work are both representations. In most cases a specific printed edition will be the source of the digital edition and must be acknowledged as such. Since printed editions are protected by copyright laws—although not to the same degree in all jurisdictions—you must ensure that you are legally entitled to use the printed edition as the source of the digital edition.
The file description
The file description element (<fileDesc>) contains the most essential
metadata: a statement of the title and author of the text, which is essential for
cataloguing and indexing (<titleStmt>); a statement of how, under
what authority, and under what license the digital text is published
(<publicationStmt>), and a description of the digital text’s
sources (<sourceDesc>).
The title statement
The title statement supplies the title and author of the digital text. In most
cases this will be the same as the title and author of the work. For
example:
<titleStmt>
<title>Sarasvatīkaṇṭhābharaṇa</title>
<author>Bhoja</author>
</titleStmt>
Very often, however, the SARIT edition will present a work along with one or more
commentaries (see “Base texts and commentaries” below). In this case, there are two (or
more) titles, and two (or more) authors. To reflect the fact that the title of the base
text will be the main title of the document, we use the attributes type and
subtype, and the authors are distinguished by their role
attribute, as
follows:
<titleStmt>
<title type="main" subtype="base-text">Tattvasaṅgraha</title>
<title type="sub" subtype="commentary">Tattvasaṅgrahapañjikā</title>
<author role="base-author">Śāntarakṣita</author>
<author role="commentator">Kamalaśīla</author>
</titleStmt>
In the following example we have a base text and two commentaries. When there is only one
author for each role, it is easy to link authors with the titles of their
works. But when there are more than one author for each role—as is the case with
multiple commentaries—we need to supply extra an extra n
attribute.
<titleStmt>
<title type="main" subtype="base-text">Aṣṭāṅgahṛdayasaṃhitā</title>
<title type="sub" subtype="commentary" n="1">Sarvāṅgasundarā</title>
<title type="sub" subtype="commentary" n="2">Āyurvedarasāyana</title>
<author role="base-author">Vāgbhaṭa</author>
<author role="commentator" n="1">Aruṇadatta</author>
<author role="commentator" n="2">Hemādri</author>
</titleStmt>
In addition to providing information about who produced the work that forms the basis of the digital text, namely the author, the title statement also provides information about who helped to produce the digital text. This includes funding agencies, principal investigators, data enterers, and so on.
The funding agency and principal investigator have their own TEI elements
(<funder> and <principal>), but it is good
practice to encode the names of persons with the general-purpose element
<persName> (further uses of <persName> will be
discussed in the full version of the
guidelines):
<funder>Deutsche Forschungsgemeinschaft</funder>
<funder>The National Endowment for the Humanities</funder>
<principal>
<persName>Birgit Kellner</persName>
</principal>
Other responsible parties should be identified with the
<respStmt>, a
“responsibility statement” that includes two further elements:
<resp>, which explains the nature of the responsibility, and an
element, usually <persName>, that identifies the responsible
party:
<respStmt>
<resp>data entry by</resp>
<name>SWIFT Information Technologies, Mumbai</name>
</respStmt>
<respStmt>
<resp>prepared for SARIT by</resp>
<persName>Liudmila Olalde</persName>
</respStmt>
The publication statement
The publication statement tells us how the digital text (not the sources of the digital text) is published. SARIT editions will have a publication statement with the following structure, although the TEI P5 http://www.tei-c.org/release/doc/tei-p5-doc/en/html/HD.html#HD24 offer additional possibilities:
- the publisher of the digital text (typically SARIT);
- its availability;
- the date of its publication;
Texts that are made available through SARIT should
include:
<publisher>SARIT</publisher>
The availability of a text can either be free or restricted, which are
the two possible values of the attribute status in the element
<availability>. Unless there are special circumstances, SARIT
texts are made available under a Creative Commons licence. This means that their
availability is restricted, since CC licences put restrictions on the further
use and reuse of documents. (Free in this case does not refer to cost; all
SARIT texts are available free of cost.) SARIT texts will therefore usually include a
<licence> element that either links to or reproduces this
licence. Here is an example of an element that links to the CC
license:
<availability status="restricted">
<licence>
<p>Distributed under a
<ref target="https://creativecommons.org/licenses/by-sa/4.0/">Creative
Commons Attribution-ShareAlike 4.0 International licence</ref>.
</p>
</licence>
</availability>
The date of publication is simply contained in the <date>
element:
<date>2014</date>
The source description
The last obligatory portion of the file description is the source description, which
tells us the sources on which the digital text is based. This will often be the most
extensive and detailed part of the TEI Header. Usually, there will be one edition that
the digital text is primarily based on. We want to distinguish this “main source” from
other sources that supplement the main source, or “second-level” sources (the sources of
the digital document’s sources). Thus, by convention, the first element in the
source description is understood to be the main source. In order to be completely
explicit, however, SARIT recommends that the role of each source in the constitution of
the digital document should be briefly explained with a <note>.
TEI provides a number of ways of tagging bibliographic information, but SARIT recommends
the use of <bibl>. This is a relatively flexible element which should
accommodate book, articles in journals, and articles in collections. The following are
examples for different kinds of printed sources. The most common is a book, which has
one or more titles (<title>), one or more authors
(<author>), usually one or more editors
(<editor>), and the standard publication information
(<publisher>, <pubPlace>, and
<date>). Note that it is best practice to encode names
of modern-day authors and editors using the <name> element and its
sub-elements, <surname> and <forename>, in order
to make it easier to sort and reformat bibliographic
entries.
<bibl>
<title type="main">Tattvasaṅgraha of Śāntarakṣita With the Commentary of Kamalaśīla.</title>
<title type="sub">Edited with an Introduction in Sanskrit by Embar Krishnamacharya with a foreword by the general editor. In two volumes</title>
<author>Śāntarakṣita</author>
<author>Kamalaśīla</author>
<editor>
<name>
<forename>Embar</forename> <surname>Krishnamacharya</surname>
</name>
</editor>
<publisher>Central Library</publisher>
<pubPlace>Baroda</pubPlace>
<date>1926</date>
</bibl>
Here is an example for journal articles, demonstrating the use of the level
attribute to distinguish between the title of the article (<title
level="a">) and the title of the journal (<title
level="j">). Note also the use of the <biblScope>
element to represent a page range.
<sourceDesc>
<bibl type="article" subtype="journal_article">
<author>
<name>
<forename>Iwata</forename> <surname>Takashi</surname>
</name>
</author>
<title level="a">Pramāṇaviniścaya III 64-67: Die Reduzierung richtiger Gründe auf den svabhāva- und kāryahetu</title>
<title level="j">Wiener Zeitschrift für die Kunde Südasiens</title>
<date when="1993">1993</date>
<biblScope unit="pp" from="165" to="200">165-200</biblScope>
</bibl>
And this is an example of an article in a collection, again demonstrating the use of the
level attribute to distinguish between the title of the article
(<title level="a">) and the title of the collection
(<title level="m"> for monograph):
<bibl type="article" subtype="book_chapter">
<author>
<name>
<forename>Jin-Il</forename> <surname>Chung</surname>
</name>
</author>
<author>
<name><forename>Klaus</forename> <surname>Wille</surname></name>
</author>
<title level="a">Fragmente aus dem Bhaiṣajyavastu der Sarvāstivādins in der Sammlung Pelliot (Paris)</title>
<title level="m">Sanskrit- Texte aus dem buddhistischen Kanon: Neuentdeckungen und Neueditionen</title>
<biblScope unit="Folge">4</biblScope>
<pubPlace>Göttingen</pubPlace>,
<publisher>Vandenhoeck & Ruprecht</publisher>
<date when="2003">2003</date>
<biblScope unit="pp" from="105" to="124">105-124</biblScope>.
<series>
<title level="s"></title>
<biblScope unit="Beiheft">9</biblScope>
</series>
</bibl>
The sources for our printed editions are almost always manuscript sources. And when the
printed editions refer to these manuscript sources, as responsible editions do, it is
useful to provide a description of the manuscript that readers of the digital text will
be able to refer to. The proper element for this description is
<msDesc>, and it is contained directly within the
<sourceDesc> element, alongside any bibliographic sources
(<bibl>).
Here is one
example:
<msDesc>
<msIdentifier xml:id="msK">
<idno>Kun-de-ling-Manuscript</idno>
</msIdentifier>
<msContents>
<msItem>
<author>Śāntarakṣita</author>
<title>Vipañcitārthā</title>
</msItem>
</msContents>
<physDesc>
<objectDesc>
<p>Palm-leaf manuscript. 89 leaves in Kuṭilā script. Apparently written in 1152 A.C. </p>
</objectDesc>
</physDesc>
<history>
<p>In June 1934, Sāṅkṛtyāyana found this manuscript in the monastery of Kun-de-ling (Lhasa). </p>
</history>
</msDesc>
The encoding description
After the file description, TEI documents require an encoding description
(<encodingDesc>). The purpose of the encoding description is to
document the choices that were made in encoding the text, especially if there may be
uncertainty or ambiguity, for instance regarding how the different layers of base text
and commentary are represented in the TEI document.
At the moment SARIT provides no specific guidelines for the encoding
description. The <encodingDesc> element of SARIT texts
generally consists of prose paragraphs (<p>) that explain the
encoding choices specific to the text. There should be no need of noting encoding
decisions that conform to these guidelines. We do, however, recommend the use of three
elements that are available in the encoding description:
<projectDesc>, <tagsDecl>, and
<refsDecl>.
The project description (<projectDesc>) is a paragraph or two that
describes the project or projects which resulted in the creation of the digital
text:
<projectDesc>
<p>Producing as part of the NEH-DFG project “Enriching Digital Texts Collections in Indology” from 2012 to 2015.</p>
</projectDesc>
The tagging declaration (<tagsDecl>) may be used to document the usage
of specific tags in the text and their rendition if applicable (see the TEI P5
guidelines: http://www.tei-c.org/release/doc/tei-p5-doc/en/html/HD.html#HD57). Most
projects will not use the tagging declaration.
The reference declaration (<refsDecl>), however, is important: it
describes the reference system used in the text. It may be a pattern of canonical
references (see the full guidelines for more details), or it may simply describe the
structure of the text in English prose, as
follows:
<refsDecl>
<p>References in this text are either in the format w.x.z or w.x.y.z.</p>
<p>w represents the <att>n</att> attribute of the highest-level
<gi>div</gi> element (an adhyāya).</p>
<p>x represents the <att>n</att> attribute of the second-highest-level
<gi>div</gi> element (a pāda).</p>
<p>y represents the <att>n</att> attribute of the third-highest-level
<gi>div</gi> element (an adhikaraṇa).</p>
<p>z represents the <att>n</att> attribute of the fourth-highest-level
<gi>div</gi> element, which contains the text of a sūtra along with
any portion of the commentary that specifically concerns that
sūtra.</p>
</refsDecl>
The revision description
This is the last obligatory portion of the TEI header. It consists of a number of
<change> elements, each of which has a who and a
when attribute. The <change> elements will typically
include a list of changes, as below (note that <list> should be a
child of <change>, not
<revisionDesc>):
<revisionDesc>
<change who="lo" when="2014-10-29">
<list>
<item>I corrected folio number 46b to 49b on p. 73.</item>
<item>I added folio number 53b, which was missing in the printed edition.</item>
</list>
</change>
</revisionDesc>
Prose paragraphs (<p>) are also permitted in <change> elements, but lists are preferred.
Base texts and commentaries
The rest of these guidelines will concern the text’s data rather than its metadata. All
of this data is contained in the element <text> that immediately
follows the TEI Header. The <text> element must contain a
<body> element which represents the body of the text; it might
also contain <front> and <back> elements,
representing any front matter or back matter, respectively. The
<text> element must also have an xml:lang attribute
that tells us what language and what script the text contained therein is written in.
Here is an example for a text encoded in Roman
transliteration:
<text xml:lang="sa-Latn">
<body>
....
</body>
</text>
And an example for a text encoded in Devanāgarī:
<text xml:lang="sa-Deva">
<body>
....
</body>
</text>
The <text> element is the last child element of
<TEI>.
A single document might contain more than one text. In particular, a single document will very often contain a commentary together with the text that it is a commentary on, hence known as the “base text.” You may only be interested in the base text, or only in the commentary. But you may also want to encode both texts, and in that case you will also want to make the relationship between the texts explicit. There are, in general, two options for encoding a base text with its commentary:
- Together. The base text and the commentary are encoded in a single document.
- Separate. The base text and the commentary are encoded in separate documents. They are linked to each other (i.e., the commentary includes references to the base text) through the procedures described in the full version of the guidelines.
For example, SARIT includes a text of the Daśarūpaka of Dhanañjaya, together with the Avaloka commentary by Dhanañjaya’s brother Dhanika. These two texts are encoded in a single document. A further commentary on the two texts, the Laghuṭīkā of Bhaṭṭa Nṛsiṃha, is encoded in a separate document that refers back to the original document.
Generally speaking, if the base text and commentary are printed in the same register on the page (the base text being in a larger font or in bold, see below example 1), it makes sense to encode them together; if the base text and commentary are printed in separate registers (see below example 2), it is easier to encode them separately.
These guidelines will tell you how to encode the base text and the commentary together. Please consult the full version for guidance on how to encode them separately.
Example 1

Example 2

The base text is a quotation
SARIT recommends a model in which the base text is “embedded” in the commentary. In other words, we presume that everything in the <text> element represents the commentary unless specified otherwise. The rest of this section will deal with how to specify otherwise.
When a base text is included or embedded within a commentary, SARIT treats it as a
special kind of quotation. It should therefore be enclosed within the tag
<quote>, which TEI uses for quoted material, and this tag will
have the attribute type="base-text". Theoretically we should be able to
extract the base text from the commentary by pulling out all of the <quote
type="base-text"> elements. In the following example the verse आनन्दनिष्यन्दिषु etc.
is marked as belonging to the base text, because it is contained within the <quote
type="base-text">
element:
<p>इदं प्रकरणं दशरूपज्ञानफलम् । दशरूपज्ञानं किंफलमित्याह—</p>
<quote type="base-text">
<lg n="6">
<l>आनन्दनिष्यन्दिषु रूपकेषु व्युत्पत्तिमात्रं फलमल्पबुद्धिः ।</l>
<l>योऽपीतिहासादिवदाह साधुस्तस्मै नमः स्वादपराङ्मुखाय ॥</l>
</lg>
</quote>
As in the above example, we recommend making the <quote> element that
contains the base text a sibling rather than a child of the elements
of the commentary (<p> and so on). That is, the
<quote> element should be a child of the same structural division
(see below) as the elements of the commentary.
Enclose the base text and commentary in a division
In almost every case, the structure of the base text and commentary will be the same. This means that a given reference, such as 1.4.5, should be able to identify both the base text and the corresponding section of commentary. The easiest way to accomplish this is to put the base text and the corresponding section of commentary within a single structural division. This enclosing division is meant to gather the two texts together for the purposes of display and reference.
The “section of a commentary” that corresponds to a section of the base text will often take the form of an optional avataraṇikā, the base text, and then a more extensive commentary. This should all be enclosed within a <div> element, as follows:
Example 3

<div n="249">
<p>स्वसम्वेदनमाख्यातुमाह (।)</p>
<quote type="base-text">
<lg n="249">
<l>अशक्यसमयो ह्यात्मा रागादीनामनन्यभाक् ।</l>
<l>तेषामतः स्वसंवित्तिर्न्नाभिजल्पानुषङ्गिणी ॥ २४९ ॥</l>
</lg>
</quote>
<p>रागद्वेषसुखदुःखादीनां सर्व्वचित्तचैत्तानामात्मसंवेदनं प्रत्यक्षमविकल्पत्वात् ।</p>
<p>तथा हि । ... न शब्दसंगतः । (२४९)</p>
</div>
Note that an n attribute is assigned to the enclosing division. This is
optional, but it helps to identify the section of the commentary with the verse-number
of the base text that it comments upon (which is identical with the n
attribute of the quoted <lg> element). The enclosing division may
also have a type attribute, such as type="sūtra", which tells
us that it gathers the portion of the commentary that concerns a given sūtra. This
attribute, too, is optional.
Here is an example without an
avataraṇikā:
<div n="7">
<quote type="base-text">
<lg n="7">
<l>अशेषशक्तिप्रचितात्प्रधानादेव केवलात् ।</l>
<l>कार्यभेदाः प्रवर्त्तन्ते तद्रूपा एव भावतः ॥ ७ ॥</l>
</lg>
</quote>
<p>यदशेषाभिर्महदादिकार्यग्रामजनिकाभिरात्मभूताभिः शक्तिभिः, प्रचितम्—युक्तं सत्वरजस्तमसां साम्यावस्थालक्षणं प्रधानम्, तत एवैते महदादयः कार्यभेदाः प्रवर्त्तन्ते इति कापिलाः । ...</p>
</div>
Several sections of the base text corresponding to one section of commentary
It may be the case that a commentary will skip one section of the base text, or comment
on several sections of the base text at the same time. In such cases, the enclosing
division will simply include more than one section of the base text. The label
(n) for this division will include all of the sections of the base text
that are comprised in the division. For example, a section of commentary that comments
upon two sūtras of the base
text:
<div n="10 11" type="sūtra">
<quote type="base-text">
<ab n="10" type="sūtra">प्रकृतिविकृत्योश्च ॥</ab>
<ab n="11" type="sūtra">वृद्धिश्च कर्तृभूम्नास्य ॥</ab>
</quote>
<p>प्रकृतिविकारभावञ्च शब्दज्ञाः स्मरन्ति ; न चायं नित्यस्योपपद्यते ; तस्मात् स्मृतिरपि पूर्वोक्तहेत्वनुगुणैव । सादृश्यमप्यनुगुणमुपलभामह इत्युपपन्नं कार्यत्वम् ॥</p>
</div>
Example 4

Sections of commentary that don’t correspond to any section of the base text
Commentaries sometimes have material that doesn’t correspond to a particular section of
the base text: the most common example is introductory material. This material, too,
must be put in an enclosing division; the only difference is that this division will not
contain any base text
elements.
<div>
<lg><l>सृष्टाविद्यानिशाध्वंसिनिबन्धमयवासरम् ।</l><l>उज्जासितजगज्जाड्यं नमस्यामः प्रभाकरम् ॥ १ ॥</l></lg>
<lg><l>प्रभाकरमयीं दृष्टिं दक्षिणां दधतं सदा ।</l><l>वामदर्शनतापन्नचन्द्रं वन्देऽपराजितम् ॥ २ ॥</l></lg>
<lg><l>प्रभाकरगुरोर्भावमतिगम्भीरभाषिणः ।</l><l>अञ्जसा व्यञ्जयिष्यन्ती पञ्चिका क्रियते मया ॥ ३ ॥</l></lg>
<lg><l>उपन्यासनिरासाभ्यां व्यासेनैषा विदूषिता ।</l><l>व्याख्या प्राचां निबन्धॄणामिति नाहमदूदुषम् ॥ ४ ॥</l></lg>
</div>
Sections of base text that are distributed across several sections of commentary
Sometimes what we think of as a single section of the base text (a verse, paragraph, etc.) is split up between several sections of commentary: for example, the commentary might take individual words from the base text in turn. Although the underlying principle is the same—put the base text elements within an enclosing division that also includes the commentary—the base text elements in this case will be fragmented, and we need to provide enough information to allow the structure of the base text to be reconstituted. Thus the elements of the base text should be labelled as specified below (in the “verse fragments” section).
Sections of the text
There are many Sanskrit words for sections of a text: sarga, adhyāya, aṅka, pariccheda, ucchvāsa, etc. The encoding of these sections should meet several requirements:
- the XML document itself should be valid;
- the structure of the XML document reflects the logical structure of the text;
- a standard reference system should be able to use the structure of the XML document as a proxy for the structure of the text;
- texts in the corpus are broadly consistent in the encoding strategy used for these sections.
These considerations lead us to recommend the use of <div> for all
"parts," "sections," and "divisions" in the text, whatever their Sanskrit name is, and
at whatever depth they occur. Do not use the numbered divisions
available in earlier versions of the TEI Guidelines (<div1>,
<div2>, etc.).
Before encoding a text, you should figure out a strategy for representing all of the
relevant levels of the text as <div> elements. Some Mīmāṃsā texts,
for example, are organized according to the hierarchical organization of the Mīmāṃsā
Sūtras into adhyāyas, pādas, and adhikaraṇas. The first <div> beneath
the <body> element (body/div) will thus correspond to an
adhyāya, the first <div> below this to a pāda
(body/div/div), and the first <div> below this
(body/div/div/div) to an adhikaraṇa. If this schema is applied
consistently, there is no need for assigning a type to the <div>
elements themselves (e.g., <div type="adhyāya">, <div
type="pāda">, <div type="adhikaraṇa">), but these
type attributes may be included in order to make the XML easier to
read.
The strategy followed in the text can be, and should be, documented in the reference
declaration (<refsDecl>), which is part of the encoding description
(<encodingDesc>) in the TEI Header (see above).
Labelling sections
Sections of the text should be identifiable. In order to be identifiable to
humans, sections generally carry a heading and/or a trailer (see below). In order to be
identifiable to machines, sections carry a numeric label that is represented by
the n attribute of the corresponding <div> element. The
value of @n will usually be the serial number of the section: <div
n="2"> represents the second division (adhyāya, pāda, adhikaraṇa, etc.),
even if it's not actually the second <div> element within its parent
element. For division that comprises more than one such section, we simply put all of
the corresponding numbers in the n attribute: <div n="2 3
4">.
Divisions (<div>s) are block-level elements, and they constitute the text
hierarchy, together with other block-level elements like paragraphs
(<p>), verses (<lg>), and the “anonymous
blocks” used for sūtras and the like (<ab>). The overall reference
system of the text will therefore usually include the numbering of
<div> elements at the upper levels and the numbering of
<lg> or <ab> elements at the lower levels.
Headings and trailers
Headings and trailers are short “paratexts” that announce the beginning or end of a section. These may be original to the text, or added by scribes or even the editor: the general rule, however, is that if it is included in the printed text, it should be included in the digital text; if you determine that the editor or a scribe was in fact responsible for adding some or all of these “paratexts,” TEI allows you to hold him responsible and ultimately filter out such interventions if desired. See “holding people responsible” in the SARIT Full guidelines.
Headings
Some sections of the text will begin with a heading, most often a short introductory
phrase (e.g., अथ भावाधिकरणम्). We encode these heading with the TEI element
<head>. There can be more than one <head>
element at the beginning of a section:
<text xml:lang="sa-Deva">
<body>
<head>श्रीः</head>
<head>अभिनवभारती</head>
...
</body>
</text>
In addition to the headings printed in the text, the heading element is a convenient
place to put chapter or section titles for a table of contents, especially if there are
no printed headings, or if they would be unsuitable for a table of contents. This is
also a way to use English or transliterated titles within a Sanskrit text (using, of
course, the relevant xml:lang attribute). You are therefore encouraged to
use the special element <head type="toc">, which will supply the
title of the section in question to the table of contents, but which is itself
suppressed in the browsing display on the SARIT website. For
example:
<div n="1">
<head>अथ प्रथमपरिच्छेदः</head>
<head type="toc" xml:lang="en">First chapter</head>
...
</div>
Trailers
SARIT uses the TEI element <trailer> for those short pieces of text
(often called colophons) that come at the end of a section. <trailer>
should typically be the final element in the element that it
closes.
<trailer>॥ इति बृहत्यां प्रथमाध्यायस्य प्रथमः पादः समाप्तः ॥</trailer>
Example 5

Milestones
SARIT recommends encoding the page and, where possible, line numbers of the source edition for purposes of reference. (The digital text will have its own lineation and pagination depending on the media in which it is viewed.) These are encoded as “milestone” elements, that is, single elements that mark the transition from one unit to the text. Sometimes other kinds of milestones besides lines and pages are noted in source editions, for example manuscript folios. Specific guidelines for the use of these elements are provided below.
Lines
If you choose to encode line-breaks at all, every single line-break of the source
edition must be explicitly represented in the digital texts. Whenever a new
line begins in the source edition, the element <lb/> must appear,
whether it occurs within a prose paragraph, or at the end of a prose paragraph; within a
metrical line of verse, or at the end of such a line. If line-breaks are encoded
consistently, there is no need to assign them a numeric label, because the line-number
can be automatically determined
The <lb/> element is assumed to refer to line-breaks in the principal
source of the digital text. (If you wish to encode line-breaks of another edition, use
the ed attribute to refer to it, and see the section on internal references
in the full version of the guidelines.)
SARIT distinguishes two types of line breaks:
- an
<lb/>between words: e.g., उक्तं <lb/>च - an
<lb/>in the middle of a word, and thus after an end-of-line hyphen. SARIT uses thebreakattribute to specify that the element "is considered not to mark the end of any adjacent orthographic token"; the hyphen itself is not encoded. For example:शं<lb break="no"/>करः
Example 6

Example 7

Pages
The pagination of the source edition is encoded by placing the element
<pb/> (for "page break") at the beginning of every new page. In
contrast to line-breaks, SARIT requires the <pb/> element to have a
numeric label (n) that corresponds to the page number. But like
line-breaks, SARIT uses the break attribute to distinguish between page
breaks that occur between words (e.g., उपपन्नम् । <pb n="2"/>यदि च)
and page breaks that occur within a word (e.g., उपप<pb n="2"
break="no"/>न्नम् । यदि च). And also like line-breaks, we assume that the
breaking element and the corresponding number refer by default to the principal source
edition.
Folios
Manuscript folios are treated as pages, so the beginning of a new manuscript folio (or a
new side of a manuscript folio) is encoded with the <pb> element.
These elements have an @ed attribute that refers to the manuscript (the
manuscript itself should be mentioned in the source description of the TEI header).
<pb ed="msK" n="2a"/>
Prose
Prose paragraphs should be encoded using TEI’s <p> element.
<p>देवमुनिगुरुनृपपुत्रविषया तु भाव एव न पुना रसः ।</p>
Verse
SARIT uses the <lg> element, a “line group,” for metrical verses. A
verse contains a number of metrical lines, which are encoded with the
<l> element. You can think of a line in the context of
verse as anything that ends in a daṇḍa or a double daṇḍa. The only things permitted in
the <lg> element are line elements (<l>) and
labels (<label>). Verses that are numbered in the edition should also
be given a label (n) by which they can be easily identified. Generally the
verse numbers in the printed text, however, should also be represented as text. That is,
the number of the verse is included both in the n attribute of the verse
element <lg>, and at the end of the second line, as
follows:
<lg n="1">
<l>वागर्थाविव संपृक्तौ वागर्थप्रतिपत्तये ।</l>
<l>जगतः पितरौ वन्दे पार्वतीपरमेश्वरौ ॥ १ ॥</l>
</lg>
Metrical lines are not typographic lines. A typographic line break, encoded as
<lb/>, might occur in the middle of, or at the end of, a metrical
line. A metrical line usually consists of two metrical quarters (pādas), and thus a
verse usually consists of four quarters. The juncture between two quarters is a kind of
break or pause, and therefore we encode it using the TEI element
<caesura/>.
Why do we use both <caesura/> and <lb/>? The
<caesura/> element encodes an element of metrical structure that
often motivates or explains the way the verse has been set on the page in the source
edition. The <lb/> element may thus coincide with a
<caesura/> element, but its primary purpose is to count the
number of line breaks on a page. For example, a digital text that does not
render line-breaks at all might encode the following
verse:
<lg>
<l>स्वसुखनिरभिलाषः खिद्यसे लोकहेतोः<caesura/> प्रतिदिनमथवा ते वृत्तिरेवंविधैव ।</l>
<l>अनुभवति हि मूर्ध्ना पादपस्तीव्रमुष्णं<caesura/> शमयति परितापं छाययोपाश्रितानाम् ॥</l>
</lg>
The lineation of the source edition does not always reflect this structure.
Here is one possible
representation:
<lg>
<l>स्वसुखनिरभिलाषः खिद्यसे <lb/>
लोकहेतोः<caesura/> प्रतिदिनमथवा ते वृत्तिरेवंविधैव ।</l>
<l>अनुभवति हि मूर्ध्ना पादपस्तीव्रमुष्णं<caesura/><lb/>
शमयति परितापं छाययोपाश्रितानाम् ॥</l>
</lg>
When the line is broken in the middle of a word, use the break="no"
attribute rather than hard-coding a hyphen into the text, as noted in the section on
milestones
above:
<lg>
<l>तिष्ठन् भाति पितुः पुरो भुवि यथा सिंहासने किं तथा<caesura/><lb/>यत् संवाहयतः सुखं हि चरणौ तातस्य किं राज्यतः ।</l>
<l>किं भुक्ते भुवनत्रये धृतिरसौ भुक्तोज्झिते या गुरो<caesura/><lb break="no"/>रायासः खलु राज्यमुज्झितगुरोस्तत्रास्ति कश्चिद् गुणः ॥</l>
</lg>
The common āryā meter and its relatives call for some comment: they are
sometimes thought of as having four quarters, and sometimes not. SARIT recommends the
use of the <caesura/> element to represent the yati between
the first and second half of the line, when it is present; when the yati is
absent, the <caesura/> element may be omitted. For
example:
<lg n="87">
<l>हुअवह-पडित्त-णूमिअ-<caesura/>णिअ-णणुम्हा-विसंठुल-मह-ग्गाहं ।</l>
<l>परिवड्ढिएक्कमेक्काणुराअ-सर-पहर-णिव्वलिअ-सङ्ख-उलं ॥ ८७ ॥</l>
</lg>
Groups of verses
Groups of verses should simply be put into another <lg> element that
encloses the <lg> elements corresponding to individual verses. If
there is a label for the group in the printed text (e.g., kulaka, yugalaka, etc.), it
should be included with the <label> element, as
follows:
<lg>
<label>जुग्गं</label>
<lg n="34">
<l>इअ पहसिअ-कुमुअ-सरे <caesura/>भडि-मुह-पङ्क-विरुद्ध-चन्दालोए ।</l>
<l>जाए फुरन्त-तारे <caesura/>लच्छि-संगाह-णव-पोसे सरे ॥ ३४ ॥</l>
</lg>
<lg n="35">
<l>झिज्जइ झीणा वि तणू <caesura/>अट्ठिअ-बाहं पुणो परुण्णं व मुहं ।</l>
<l>रामस्स अईसन्ते <caesura/>आसा-बन्धे व्व चिर-गे हणुमन्ते ॥ ३५ ॥</l>
</lg>
</lg>
Fragments of verses
Sometimes the parts of a verse are broken up within a text, for example when a
commentator breaks up a verse to discuss its components separately. In these cases,
every verse-fragment should be contained in an <lg> element with the
attributes next, prev, or both.
All of the verse-fragments should have an identifying label (a, b, c, etc.), e.g.
n="27c". The value of next and prev should
refer to these identifying labels, e.g., next="27d".
The labelling convention will allow applications to identify “verse 27” as the sum of its
parts in case there is no element <lg n="27"> to be found. However, it
will not join fragmentary <l> elements into a single element.
Therefore it is recommended to use the part attribute on any fragmentary
<l> attributes: I for an initial fragment (e.g.,
pādas a or c) and F for a final fragment (e.g., pādas b or d), or
M for a medial fragment if such a case occurs.
Example 8

<div type="section" n="27c">
<p><hi>परिन्यास</hi>माह—</p>
<quote type="base-text">
<lg n="27c" prev="27b" next="27d">
<l part="I">
तन्निष्पत्तिः परिन्यासो
</l>
</lg>
</quote>
<p>
यथा तत्रैव <note>(रत्ना॰ १।८)</note>—
<lg>
<l>प्रारम्भेऽस्मिन् स्वामिनो वृद्धिहेतौ दैवे चेत्थं दत्तहस्तावलम्बने ।</l>
<l>सिद्धेर्भ्रान्तिर्नास्ति सत्यं तथापि स्वेच्छाकारी भीत एवास्मि भर्तुः ॥</l>
</lg>
इत्यनेन यौगन्धरायणः स्वव्यापारस्य दैवयोगात् निष्पत्तिमुक्तवानिति परिन्यासः ।
</p>
</div><!-- section -->
<div type="section" n="27d">
<p><term>विलोभन</term>माह—</p>
<quote type="base-text">
<lg n="27d" prev="27c">
<l part="F">
गुणाख्यानाद् विलोभनम् ॥ २७ ॥
</l>
</lg>
</quote>
</div><!-- section -->
Example 9

<div n="210">
<quote type="base-text">
<lg n="210a" next="210b">
<l>किं स्यात् सा चित्रतैकस्यां;</l>
</lg>
</quote>
<p>ननु यदि सा चित्रता बुद्धावेकस्यां स्यात् तया च चित्रमेकं द्रव्यं व्यवस्थाप्येत (।) तदा कि दूषणं स्यात् ।</p>
<p>आह (।)</p>
<quote type="base-text">
<lg n="210b" prev="210a" next="210c">
<l>न स्यात्तस्यां मतावपि ।</l>
</lg>
</quote>
<p>न केवलं द्रव्ये तस्यां मतावप्येकस्यां न स्या च्चित्रता । आकारनानात्वलक्षणत्वाद् भेदस्य । नानात्वेपि चित्रता कथम् (।) अनेकपुरुषप्रतीतिवत् ।</p>
<p>कथन्तर्हि प्रतीतिरित्याह (।)</p>
<quote type="base-text">
<lg n="210c" prev="210b">
<l>यदीदं स्वयमर्थानां रोचते तत्र के वयम् ॥ २१० ॥</l>
</lg>
</quote>
<p>यदीद</q>मताद्रूप्येपि ताद्रूप्यप्रथनमर्थानां भासमानानां नीलादीनां स्वयमपरप्रेरणया रोचते । तत्र तथाप्रतिभासे के वयमसहमानाऽ(? अ) पि निषेद्धुं । अवस्तु च प्रतिभासते चेति व्यक्तमालीक्यं । (२१०)</p>
</div>
Verses within prose paragraphs
Often verses are “embedded” into paragraphs, and we reflect this fact by embedding the
<lg> element into the <p> element.
Sūtras
Sūtras are like paragraphs, but they are often formatted differently (without
indentation, for example) and they do not have the “semantic baggage” of a prose
paragraph. SARIT recommends the use of the <ab> element (“anonymous
block”) with the attribute type="sutra".
In the following example, the <ab> element includes, in addition to
the text of the sutra, two typed labels that provide, respectively, the serial number of
the adhikaraṇa in which the sutra occurs, and the position (pūrvapakṣa,
uttarapakṣa, or siddhānta) that the sutra represents.
Example 10

<ab type="sutra" n="2">
<label type="adhikarana">2</label>
<label type="position">सि॰</label>
एकस्यैवं पुनः श्रुतिरविशेषादनर्थकं हि स्यात् ॥ २
</ab>
<p> समिधो यजति, तनूनपातं यजति इत्येवमादिः पञ्चकृत्वोऽभ्यस्तो ...
Dramatic elements
SARIT uses the core elements of the TEI’s drama module for Sanskrit plays. Plays usually
consist of divisions, such as an aṅka, in which various characters speak lines in prose
or verse. The standard element for a “line” in this sense is <sp>:
this contains the lines spoken by the character, either as prose
(<p>) or verse (<lg>).
The <sp> element may also contain a label for the speaker and stage
directions. The speaker is encoded in the element <speaker>, and
stage directions in the element <stage>. You should omit any
formatting the editor has used to distinguish these elements.
Example 11
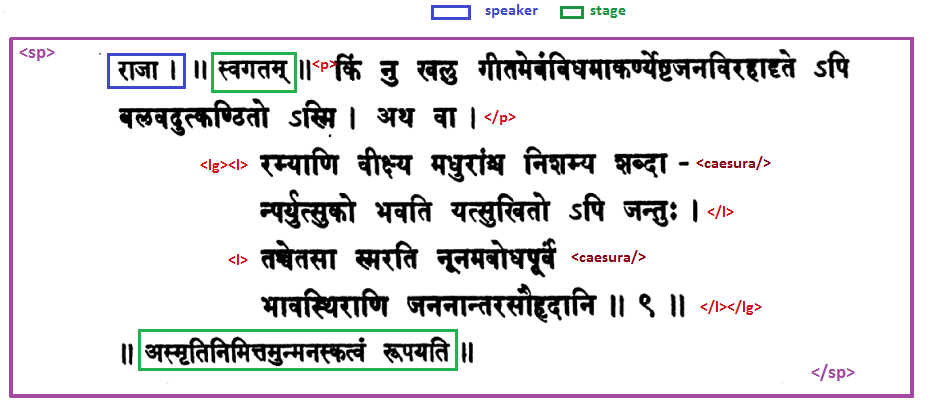
<sp>
<speaker>राजा</speaker>
<stage>स्वगतम</stage>
<p>
किं नि खलु गीतमेवंविधमाकर्ण्येष्टजनविरहादृते ऽपि बलवदुत्कण्ठितो ऽस्मि । अथ वा ।
</p>
<lg>
<l>रम्याणि वीक्ष्य मुधरांश्च निशम्य शब्दा<caesura/>न्पर्युत्सुको भवति यत्सुखितो ऽपि जन्तुः ।</l>
<l>तच्चेतसा स्मरति नूनमबोधपूर्वं<caesura> भावस्थिराणि जननान्तरसौहृदानि ॥ ९ ॥</l>
</lg>
<stage>अस्मृतिनिमित्तमुन्मनस्कत्वं रूपयति</stage>
</sp>
Labels and notes
The source edition will sometimes have labels added by the editor, which
help to identify sections (below the level of the sections explicitly encoded as
<div> elements), positions in an argument (pūrvapakṣa,
uttarapakṣa, siddhānta), or other features of the text. It will
also sometimes have notes, whether those are represented as footnotes,
endnotes, or otherwise. It is possible to represent both labels and notes using TEI’s
<label> and <note> elements.
Because SARIT recommends encoding structure rather than presentation,
it is important to have an encoding strategy for representing various types of notes and
labels, and to document this strategy in the encoding declaration of the header. For
example, your text might list variant readings and references in the footnotes, and
hence you might encode these notes as <note type="text-critical"> or
<note type="reference">. Similarly, it is recommended to find
consistent type attributes for <label> elements as well,
and to avoid the use of formatting-specific attributes (like place and
rend).
In the example below the labels might be encoded as
follows:
<label type="position">2</label>
<label type="position-person">भामहः</label>
<lg>
<l>अगोनिवृत्तिः शब्दार्थो यदि गौः केन गम्यताम् ।</l>
<l>गोशब्दं शृण्वतः पूर्वमगौः स्फुरतु चेतसि ॥ ५ ॥</l>
</lg>
Example 12

Notes are often represented in printed editions with a note marker in the main
text, and the note text either at the bottom of the page (as footnotes) or at
the end of the chapter or text (as endnotes). SARIT embeds notes into the text in
their proper place. That is, wherever you see a note marker in the text, that
is where you should place the <note> element.
The content of the <note> element depends on the type of
note that it represents. Typically, however, notes will contain a <p>
element. For text-critical notes, the simple version of the guidelines recommends the
use of prose paragraphs; more sophisticated methods are available in the full version of
the guidelines.
Attention must also be paid to the language of the note, since in many cases it
will differ from the language of the surrounding text. It is good practice to use the
xml:lang attribute to identify the language of any element that differs
from its parent element. This also includes sections of Sanskrit text quoted in notes,
for which you may use the <foreign> element. For example:
<p>यं नाट्यवेदं वेदेभ्यः सारमादाय ब्रह्मा कृतवान्,
यत्संबद्धमभिनयं भरतश्चकार करणाङ्गहारानकरोत्<note
xml:lang="en"><p>A.T.A. <foreign
xml:lang="sa-Latn">hārān anekān
akarot</foreign>.</p></note>
Note, finally, that editors will often insert references into the text itself,
and you are encouraged to use the <note> element for these additions,
as in the following example. (See the full version of the guidelines for instructions
regarding pointing references and canonical reference
schemes.)
<p>यथा तत्रैव (<note type="reference">रत्ना॰ १।८</p></note>—
<lg>
<l>‘प्रारम्भेऽस्मिन् स्वामिनो वृद्धिहेतौ दैवे चेत्थं दत्तहस्तावलभ्बे ।</l>
<l>सिद्धेर्भ्रान्तिर्नास्ति सत्यं तथापि स्वेच्छाकारी भीत एवास्मि भर्तुः ॥’</l>
</lg>
Quotations
For the simple level of text encoding, we recommend encoding quotations “as-is.” That is,
if the editor has used quotation marks or double quotation marks, put them into the
digital text; if the editor has used bold-face text to represent quotations, use the
<hi> tag (for “highlighted”). The reason for encoding quotations
“as-is” is the possibility that identifying the beginning and end of quotations may
require extensive checking by skilled readers, and the frequency with which quotations
are represented inconsistently in printed editions. Of course, if project resources
allow, quotations can be encoded by following the suggestions in the full version of the
guidelines.
Where do I put इति?
The particle इति, which marks quotations in Sanskrit, can be tricky: it often combines with the previous or following word, which can often mean that there is no typographic separation between a “verse” and the prose it’s embedded in. While there are ways of marking the beginning and ending of quotations, discussed more extensively in the SARIT Full guidelines, we don’t worry about quotations in SARIT Simple, and we are free to adopt the following straightforward principle: follow the typography of the printed edition.
If the edition prints इति on the same line as the verse, include it there, within the
<l> element; if it prints इति on a following line, then put it
outside of the <lg> element.
Example 14: इति on the same line

<lg>
<l>"वस्तूपलक्षणं यत्र सर्वाम् प्रसज्यते ।</l>
<l>द्रव्यमित्युच्यते सोऽर्थो भेद्यत्वेन विवक्षितः ॥" इति ।</l>
</lg>
Example 15: इति merged with the last word in a verse

<lg>
<l>एकप्रत्यवमर्षस्य हेतुत्वाद्धीरभेदिनी</l>
<l>एकधा हेतुभावेन व्यक्तीनामप्यभिन्नतेति ॥ (२५)</l>
</lg>
Example 16: इति on the following line

<p>तदयुक्तं ।
<lg><l>"तद्गतावेव शब्देभ्यो गम्यतेऽन्यनिवर्त्तनं ।</l>
<l>न तत्र गम्यते कश्चिद्विशिष्टः केनचित्पर" ॥</l></lg> (प्र. वा. १ । १२८)
इति ग्रन्थविरोधात् । नीरूपस्य चास्तित्वविरोधाच्छशविषाणवत् । नीरूपत्वा-
देव च न तस्याः प्रत्यक्षं ग्राहकं नाप्यनुमानं । सम्बन्धाभावात् ।</p>
Glossary
- base text: The text on which the current text is a commentary. Since a base text only makes sense in relation to a commentary on it, this term is only used within a commentary. Sections of the base text that are quoted in the commentary (the current text) are enclosed in <quote> elements with the @type="base-text".
- mūla: see base text.
- root text: see base text.